Introduction Link to heading
Recently Airbus Intelligence has published a few Machine Learning Datasets on the Kaggle platform. These datasets are samples from much larger and more comprehensive datasets provided by Airbus. Nevertheless, they are good datasets to start with and build upon if you wish to learn more about Earth Observation imagery and Deep Learning.
In this article, we will analyse the Airbus aircraft dataset. It contains one hundred civilian airports and a little over 3,000 annotated commercial aircrafts. Using this dataset, we will build an aircraft detector based upon the YOLOv5 framework from Ultralytics and test it on some sample images.
If you want to look at some code, you can follow along with the associated Kaggle notebooks:
- https://www.kaggle.com/jeffaudi/eda-airbus-aircrafts-dataset-sample
- https://www.kaggle.com/jeffaudi/aircraft-detection-with-yolov5
Dataset analysis Link to heading
The dataset contains 103 images for train and 6 extra images for evaluation (no annotations provided). The images are actually 2560 pixels by 2560 pixels images in RGB (3 bands) in JPEG format. They are extracted from the Pleiades archive and provided at a resolution of 50 cm per pixel. They come from various locations all over the Earth. Some airports are captured more than one to provide diversity in the location of aircraft, the acquisition angles, and the weather conditions (here below with some light clouds)

The annotations are provided as a CSV file with reference the image, geometry as a closed polygon, and class. There are 3,425 annotations for aircraft including aircraft truncated at the border of the imagery.
There are actually two classes :

There is a minimum of 5 aircraft per image to a maximum of 92 aircraft per image.
From the bounding boxes, we can compute the width and height (not the wingspan and length, though). We can display the distribution of width and height of bounding boxes.
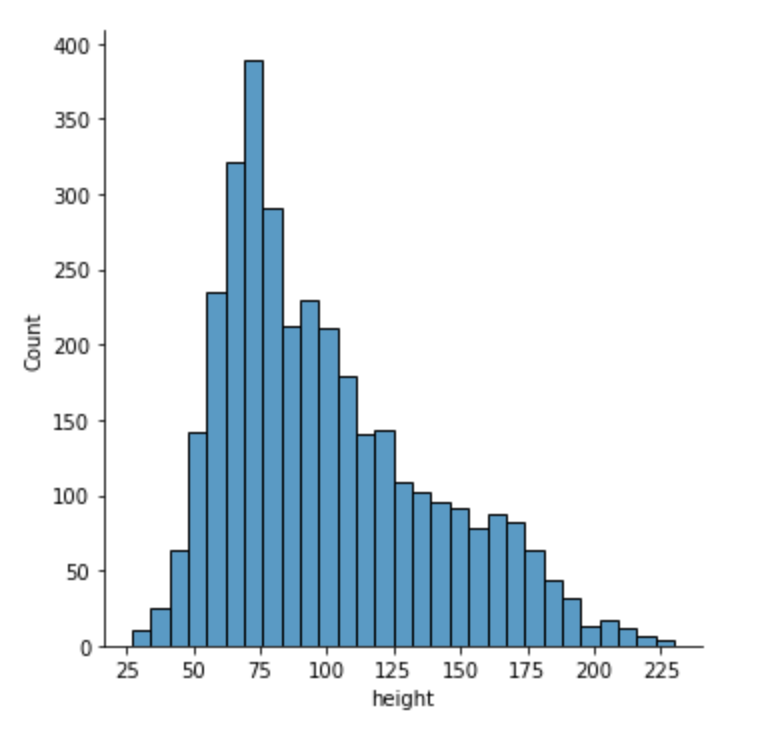
This seems correct with bounding boxes ranging from 14 m. to 115 m. The wingspan of an Airbus A380 is 80 m. for a length of 72 m. Taking into account the various orientations of the planes, this leads to a maximum of 113 m. Aircrafts smaller than 10 m in length or wingspan will probably not be detected with YOLO because of the nature of the architecture. Using ensembling with a segmentation model is probably the right way to go.
Training YOLOv5 Link to heading
In this article, we will use the YOLOv5 framework from Ultralytics. Please visit these links for more information.
The images are too big for YOLO to learn correctly. We need to make smaller images (or tiles). There are multiple options to do this. Here, we generate the tiles in advance with a selected size of 512 pixels by 512 pixels. In order to make sure that every aircraft can be seen by the network in full, we allow for an overlap of 64 pixels between the tiles. And we generate the tiles in the folder /kaggle/working. You can find the code in the Kaggle notebook.
# Create 512x512 tiles with 64 pix overlap in /kaggle/working
TILE_WIDTH = 512
TILE_HEIGHT = 512
TILE_OVERLAP = 64
TRUNCATED_PERCENT = 0.3
This will generate a lot of truncated objects but the network will be able to detect the truncated airplanes if enough structure is visible. So, we will remove the annotation only if there is less than 30% of the bounding box left visible on the image.
We should also fuse the two classes (Aircraft and Truncated_Aircraft) and remove the annotation based on the aspect ratio of the bounding box. Typically, compute width / height and remove what is too small or too large for an airplane.
**BEWARE, do not perform the split on the tiles but on the source images.**The tiling is done according to the split between training and validation. The tiles from the same image should fall in the same group. Otherwise, you will have data leakage between the train and validation and your validation set will be quite useless.
The YOLOv5 framework has a lot of embedded features. It will automatically find the correct anchors and learning rate. It also has basic data augmentation. The logs are automatically exported to Weights and Biases (WandB) which is useful since Kaggle does not offer TensorBoard anymore.
Here are the results after 10 epochs:
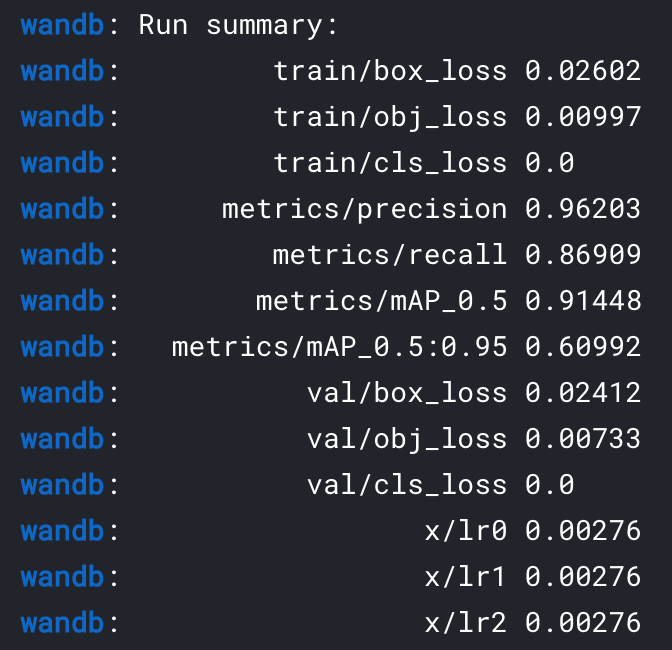
So, after a few epochs and no specific tuning, we already get an accuracy of 87% meaning that 13 aircraft out of one hundred are missed. And we get a precision of 96% which indicates that out of one hundred detected aircraft only 4 are actually not aircraft (i.e. false alarms).
Of course, this can be improved but seems pretty good already. We can run some predictions on the sample imagery and display them. Here is one:

Next steps Link to heading
You can play along with the notebooks and change some of the preprocessing parameters — tile size, tile overlap, truncated ratio. You can also change the parameters of the YOLOv5 model and check how you can improve the accuracy.
Another next step is clearly to improve the dataset by including more images and more diversity in aircraft (typically adding small aircraft — private jets, leisure aircraft — and military aircraft — fighters, bombers, and so on. You can do this by hand or by running your new detector on archive satellite imagery. You can also look into new innovative ways like using synthetic data to improve your detector.
You can also learn how to publish your inference code as a Docker container and host it on an analytics platform like UP42. You can copy some boilerplate code from UP42 Github and follow along with their documentation. This will enable you to run your algorithm at scale on some fresh imagery.
Remember that the Airbus dataset is provided under a Creative Commons BY-NC-SA license. So, this is mostly to learn, test and share with friends, students and colleagues. It cannot be used in commercial applications. If you want more imagery and licence rights, visit the Airbus OneAtlas platform.
Also, the YOLOv5 framework is provided under a GNU General Public License. This means that you can make commercial use of the software but that, if you modify it, you need to publish your modification and make sure that you attribute correctly the source.
Ready to take off and improve your skills?
Written on September 16, 2021 by Jeff Faudi.
Originally published on Medium