Lessons Learned from the Airbus Ship Detection Challenge Link to heading
In 2018, my team at Airbus Defence and Space Intelligence and I organized a machine learning challenge on the well-known Kaggle platform (see https://www.kaggle.com/c/airbus-ship-detection). At the time, there were discussions internally about the interest of such an initiative, the concrete benefits that we could gain from it, and the potential risks of open-sourcing our imagery.
One year later, we have no doubt that it was worth it. Nevertheless, the road has been somewhat hectic and we have realized that good preparation saved us from a few potential traps.
This is what I would like to share with you.
The Backstory Link to heading
Shipping traffic is growing fast and with this the chances of incidents at sea such as environmentally devastating ship accidents, piracy, illegal fishing, drug trafficking, and illegal cargo movement. This has compelled many organizations, from environmental protection agencies to insurance companies and national government authorities, to keep closer watch over the open seas.
Airbus offers comprehensive satellite-based maritime monitoring services by building a meaningful solution for wide coverage, fine details, intensive monitoring, premium reactivity and interpretation response. Combining its proprietary data with highly trained analysts, Airbus helps support the maritime industry by increasing knowledge, anticipating threats, triggering alerts, and improving efficiency at sea.
Considerable work has been done over the past 10 years to extract ship location from satellite images, but alas, with no real effect on our operations because these tools are not fully automatic. Up until now, we continue to rely on human specialists to analyze satellite imagery. But, as we acquire more and more imagery each day, we want our analysts to focus on the images with the most value. Using artificial intelligence to pre-screen images and pinpoint to the most interesting areas to investigate further would definitely be a game changer in the industry. That is why detecting ships automatically in satellite imagery is one of our holy grails!
We knew that deep learning algorithms perform very well on satellite imagery. We had successfully used this technique to automatically detect clouds in our satellite imagery so that we could provide cloudless imagery to our clients. I also took good note of two past Kaggle competitions organized on satellite imagery by DSTL and Planet. All this triggered my interest in hosting a Kaggle competition for Airbus. So during the spring of 2018, we turned to Kagglers to increase the accuracy and speed of our automatic ship detection algorithm.
Preparing the Competition Link to heading
Preparing the elements of the competition was an important step. We had been working for a year to create an algorithm to detect ships in satellite imagery. This gave us a few ideas on how we should collect our dataset. In general, there are a few very important characteristics that your dataset should have:
- It should be aligned with your users’ expectations;
- It must be large enough (for us, this meant representing the whole variety of the seas);
- It must be balanced in classes or presence/absence of objects;
- It should be aligned with the metrics that you will select to evaluate competitors;
- And it should be provided under a liberal license, usually open-source or at least non-commercial
Thus, first and foremost, we needed to be clear on what needed to be found in the imagery and what should be considered as a vessel or not. This happened through discussion with experts and users, and involved exploration of a variety of different questions. Clearly docks are not ships but are we interested in identifying barges (which are, more or less, floating and moving docks)? Are leisure boats of interest? Are we interested to count every single ship in a marina or just interested to detect the marina itself? As we were browsing through imagery, further questions arose, too: Do we want to capture the big floating cages in which some countries raise tuna? How should we label a ship inside a floating dry dock? Should we label hovercraft? While making these decisions, we integrated business needs as well as technical feasibility — we needed to make sure the task was not too difficult for the machine learning algorithm while preserving the business value. For example, we decided to keep all floating objects in the dataset but added some labels to enable us to filter or group objects later.
Secondly our dataset had to be representative of the variety of seas in the world. In some places, the sea looks blue from above as expected, but in many other places, it can look black or green or brown, like river deltas in China. There are also a number of occasions in which the sea reflects the light of the sun into the satellite camera, so that suddenly everything is inverted and ships appear as black shapes on a white surface.

Third, a machine learning dataset is better when it is balanced, i.e., with equal representation of all classes. In our case, it was not about types of ships but rather about the balance between large ships, small ships, and no ships. The high seas are mostly empty of ships. If we had merely extracted images from our archive, we would have ended up with a huge amount of empty images. So we reduced the number of images with no ships but kept the imbalance representative, i.e., two thirds of the images had no ships in them.
Fourth, you need to select a metric to measure the performance of each participant results. Note that you need to choose the metric that at the beginning of the competition but that it will influence tremendously on the results that you receive. As a matter of fact, each participant will strive to optimize his or her code to get the best score. So choosing the metric used for scoring is a very critical subject and probably deserves another future article. In our case, we choose the F2 score at different intersection over union (IoU) thresholds as described here.
Last of all, remember that when you host a Kaggle competition, you will be releasing your dataset publicly. Do not include anything confidential or secret in the dataset. You need to be clear with stakeholders and verify with your legal team that you are going to make this dataset open-source and that it will stay available on Kaggle for at least the duration of the competition. After all, hosting a competition is also about communication and reaching out to a new community of users. If you are ready, you will discover that data scientists can use your dataset in completely unexpected — and sometimes very interesting — ways.
Interacting with the Kaggle Community Link to heading
The Kaggle community is vibrant and energetic. Most users are on Kaggle for a few months to learn data science. Others are regular users and want to learn new techniques or apply their skills to new domains. And a few of them are prize hunters and serial winners!
The forums are a very lively place with lots of discussion as well as sharing of information and expertise. Usually the host just publishes a welcome message and a closing message in the forum, but I found that monitoring and reading the forums was extremely enriching.
As you will probably notice, not everything happens on the Kaggle forum, and there is a huge community of very skilled data scientists who exchange on another platform called ODS.AI. And this is why I regret not having taken Russian lessons in high school as a lot of discussion happen in Russian among participants from the former Soviet Union countries (Ukraine, Belarus, Russia, Kazakhstan, etc.). As we will discover, these countries are well represented among the winners of our competition, probably thanks to their remarkable mathematical and physics backgrounds. This is definitely something to keep in mind, especially if you are working with your human resources team and wish to discover potential talent and new hires. They might be located anywhere in the world, but are most probably in Eastern Europe and China.
There is one space where foreign languages were not an issue:the Kaggle Notebooks which enable exchange between the participants through direct code sharing. These Notebooks are cloud computing notebook resources that are provided free of charge by Kaggle. This includes a specific processing card called a graphical processing unit (GPU), which accelerates training of convolutional neural networks. The notebooks are an extremely powerful tool for sharing code. At the end of our ship detection competition, there were at least 100 different fully executable notebooks available for anyone who was interested in learning about our imagery, and about object detection in imagery as a whole.
However, the forums can become heated when something goes wrong — as happened in our case. After one month of competition, and one month ahead of its end, one Kaggler published a post called “Major leak”. Actual images extracted from the same original satellite acquisitions were present in the training and validation datasets. With a little work to reconstruct the original satellite images, it was possible to use the ground truth that we had provided to create an almost 100% accurate submission. The competition was ruined and everyone complained about the loss of their time, energy, and computing power.
You can never be fully ready for failure, yet you should prepare for it. With so many smart people looking at your data, you should not expect that errors will go unnoticed. Somewhere in the process of preparing and releasing the dataset, something had gone wrong for us. There was no way to undo it. Our decision was to speak truthfully on the forums and apologize for the issue. After all, there were all human beings behind the platform and errors could always happen. Luckily for us, we have a huge archive of imagery, and we were able to create a new validation dataset — not without some extra work, added stress and late evenings, of course. But we managed to create a new one composed only of newly acquired imagery that we were absolutely sure were not included in the previous sets. This will probably not be the case in every industry, but it was the case for us, and so, after two months, we were able to restart the competition. It helped enormously to be as humble and transparent as could be with the Kaggle community.
Leveraging the Outcome Link to heading
We were thus able to progress towards the end of our ship detection competition without much more trouble. A leaderboard is used to rank each participant according to their score. Their score is measured by applying the metric (see above) to measure the difference between their predicted results on the validation and the ground truth that is kept secret on Kaggle. Below is the public leaderboard on October 21st. The public leaderboard is computed on only a fraction of the validation data.
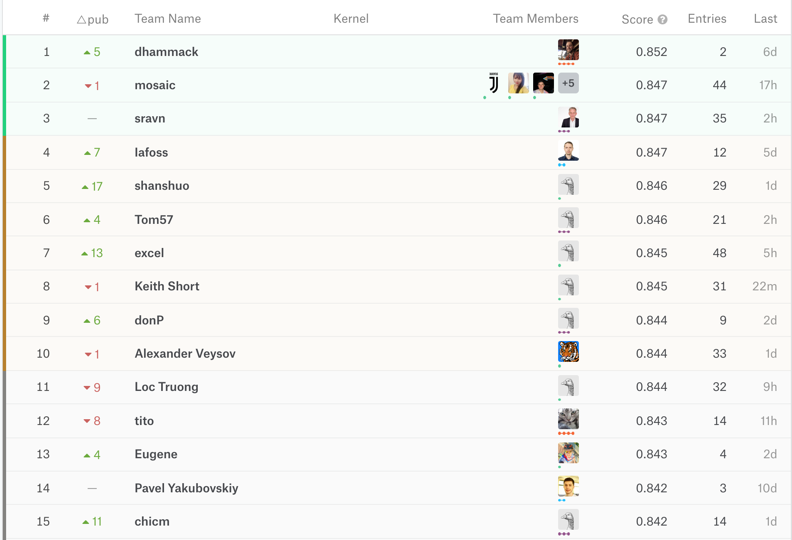
In our case, since our validation dataset was not very large (because we had to recreate a new one in a short time), there was quite a shakeup when the private leaderboard (with the score computed on all the validation data) was published on November 14th. The participants who stayed at the top were the ones who had succeeded to create a model which generalized well (i.e. did not overfit on the smaller validation dataset). It is interesting to notice the very small increase in the score over the last month of the competition.
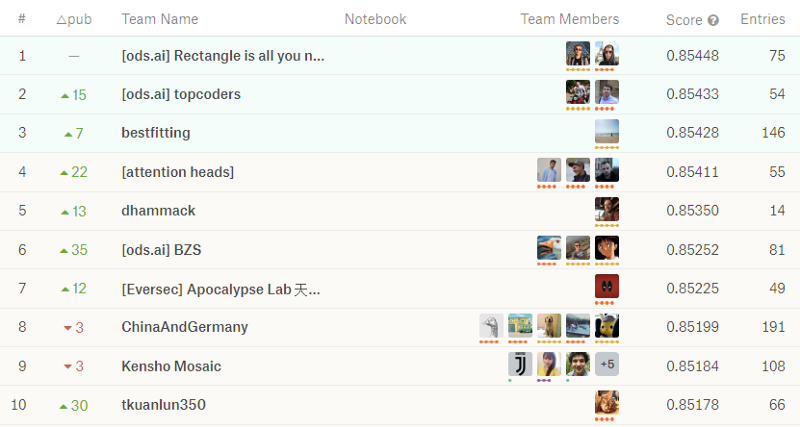
This competition was clearly not for newcomers. Just look at all the medals displayed by the top ten participants! Probably because the dataset was pretty large (29 GB) and required specific hardware (GPUs) to train. Probably also because the prize money (US$ 60.000) was large enough to attract seasoned participants. Anyhow, we were able to get more than 800 participants enrolled, and there was an interesting competition for the top three places until the last hours. Note how the difference is only in the third decimal place of the metric, and how some participants created large teams while others worked alone. I was also pretty interested in the number of entries: the lower the number, the more confident the user was about his or her skills and results.
While this is where the competition ended for the participants, it was just the beginning of the third phase for us. In exchange for the prize money, we now collected the source code of the winners and had to examine and understand it. So we needed to examine it and understand it. Fortunately, and probably naturally, due to the nature of the competition metric, the scheme was always the same: a classification model to sort the images with and without ships, followed by a segmentation model to detect the ships. Most participants used ensembling of various models and a few tricks to segment the data and the objects (most notably by creating an extra channel for ship boundaries). You can find all this in the posts and kernels of the competition.
After analyzing the code, we had to rewrite portions of it in order to make it secure and create a standalone package (typically a Docker image). We were then able to run all three winning algorithms on yet another set of ground truth images — our secret, internal qualification dataset. This dataset contained real operational images, including some with difficult sea conditions and scattered clouds representative of our day-to-day activity. The validation process was interesting because we discovered that the second-place winners actually created the model that generalized the best for new, previously unseen images. This is the one that we selected for our internal production tool after having made sure that we could fully retrain it from scratch. Compared to the algorithm that we had created internally, we were able to increase precision from 70% to 90% without decreasing recall. This means that we were able to reduce false alarms without missing any extra ship — which is usually the tradeoff. And this was a true game changer for our clients. One year down the road, we have retrained it multiple times over a progressively larger training dataset so that it can suit the needs of our increasingly demanding customers.
At this point, we realized that the particular ‘Speed Prize’ that we had created was rather impractical. Although the idea of getting an algorithm that was almost as good as the top 100 competitors but was also very fast was a good one, we could not achieve it with this competition. This was because, first of all, the number of participants who were willing to enroll in an extra part of the competition was very small; and second, because our users were not ready to accept an algorithm with reduced accuracy. Since we were able to scale the final algorithm in the cloud on multiple GPU processors, we simply decided to throw a little more money on computing power and get the processing done in the time that we wanted.
As a main takeaway, remember that the most important work that you will have to do if you plan for such a competition comes before and after it. Before, you need to craft the perfect competition by creating a unique, balanced, global dataset and wisely selecting the unique metric that will capture all the needs of your stakeholders. Afterward, you need to analyze and benchmark all the solutions to find the one that generalizes the best and that you will be able to retrain to respond to the ever evolving needs of your customers.
What are the next steps for us and you? Link to heading
We are working hard to launch a new Kaggle competition in the coming months, making sure we offer an exciting challenge to Kagglers as well as solve an important problem for our clients and partners, while at the same time giving enough attention to all the previous mentioned details.
What about you? Do you plan to organize your own competition and see for yourself how openness and sharing can deliver more value to your company than working behind closed doors? And if you have already organized such a competition, what are your experiences?
Written on March 8, 2020 by Jeff Faudi.
Originally published on Medium