We finished training and evaluation of Oriented R-CNN 3× on DOTA le90. With it, the OrientedDet pretrained zoo on Hugging Face (dl4eo/oriented-det-pretrained) is complete for our three detector families: Oriented R-CNN, Rotated Faster R-CNN, and Rotated RetinaNet.
This post focuses on the new checkpoint — why it matters, how it compares to our 1× run and to MMRotate, how to load it, and how odet image-demo runs sliding-window inference on images larger than 1024×1024.
Headline result Link to heading
| Oriented R-CNN 1× | Oriented R-CNN 3× | Δ | |
|---|---|---|---|
| eval-val mAP50 | 74.79% | 79.40% | +4.6 pp |
| Training | 12 epochs (~2 days) | 36 epochs (~6 days) | LR milestones 8/11 vs 24/33 |
| Hub slug | oriented_rcnn_dota_le90_1x | oriented_rcnn_dota_le90_3x |
eval-val means the published protocol: all 7,669 DOTA val tiles (filter_empty_gt=false), rotated IoU ≥ 0.50 for matching, production decode from the experiment config. Same setup as make eval-val in the repo.
The 1× model already matched our training recipe; the 3× schedule adds +4.6 pp on the full val split and beats the MMRotate Oriented R-CNN 1× reference (75.69%) by +3.7 pp.
Training-time periodic mAP (non-empty val tiles only, tighter internal NMS) peaks at 82.0% at epoch 36 — useful for monitoring, but not the number we publish on the Hub.
How the three families compare (eval-val mAP50) Link to heading
All models: ResNet50-FPN, 1024×1024 tiles, DOTA train+val pretrain, val-only evaluation.
| Model | Schedule | eval-val mAP50 | Hub slug |
|---|---|---|---|
| Oriented R-CNN | 1× | 74.79% | oriented_rcnn_dota_le90_1x |
| Oriented R-CNN | 3× | 79.40% | oriented_rcnn_dota_le90_3x |
| Rotated Faster R-CNN | 3× (ProbIoU) | 83.42% | rotated_faster_rcnn_dota_le90_3x |
| Rotated RetinaNet | 1× | 64.14% | rotated_retinanet_dota_le90_1x |
| Rotated RetinaNet | 3× | 71.52% | rotated_retinanet_dota_le90_3x |
Update (July 10, 2026): The
rotated_faster_rcnn_dota_le90_3xslug originally shipped at 76.41% with Smooth L1 regression. The published checkpoint now uses ProbIoU as the main ROI loss and reaches 83.42% eval-val mAP50. See Rotated Faster R-CNN on DOTA without custom CUDA for the full story. A CE baseline at 75.58% remains asrotated_faster_rcnn_dota_le90_3x_ce.
Recommendation: use rotated_faster_rcnn_dota_le90_3x for best accuracy on DOTA-style oriented detection (83.42%). oriented_rcnn_dota_le90_3x remains a strong alternative (79.40%) when rotated RoIAlign behaviour matters for your domain. Keep 1× checkpoints for faster iteration or when GPU time is limited.
Per-class reports: docs/eval-reports/ in the repo (markdown + analysis JSON; raw predictions.json stays local for the Gradio viewer).
Training curves (periodic validation mAP50) Link to heading
During training we log mAP every 4 epochs on the filtered val split (3,121 non-empty tiles). The chart below shows how 1× (12 epochs) and 3× (36 epochs) behave for each architecture. 1× runs stop at epoch 12; 3× runs continue with LR decays at epochs 24 and 33 (Oriented R-CNN / RetinaNet) or similar milestones.
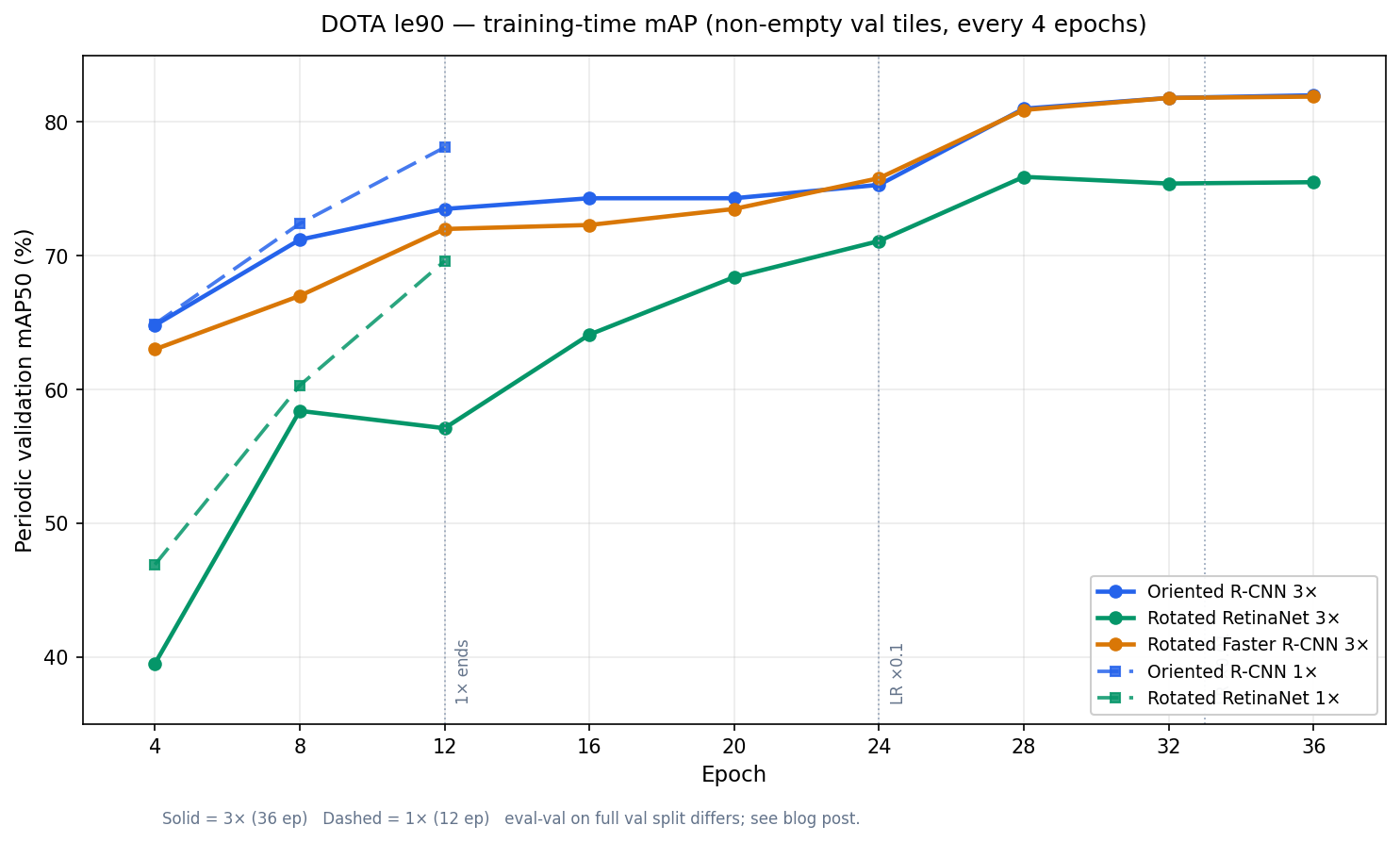
| Epoch | ORC 1× | ORC 3× | RetinaNet 1× | RetinaNet 3× | Faster R-CNN 3× |
|---|---|---|---|---|---|
| 4 | 64.9 | 64.8 | 46.9 | 39.5 | 63.0 |
| 8 | 72.4 | 71.2 | 60.3 | 58.4 | 67.0 |
| 12 | 78.1 | 73.5 | 69.6 | 57.1 | 72.0 |
| 16 | — | 74.3 | — | 64.1 | 72.3 |
| 20 | — | 74.3 | — | 68.4 | 73.5 |
| 24 | — | 75.3 | — | 71.1 | 75.8 |
| 28 | — | 81.0 | — | 75.9 | 80.9 |
| 32 | — | 81.8 | — | 75.4 | 81.8 |
| 36 | — | 82.0 | — | 75.5 | 81.9 |
Reading the Oriented R-CNN 3× curve: mAP stays near 74–75% through epoch 24, then jumps to ~81% after the first LR decay — most of the 3× gain comes from the low-LR phase, not from extra epochs at full LR. At epoch 12, the 1× run is actually ahead of 3× on this monitor (78% vs 74%) because the 1× schedule has already stepped LR down; the fair comparison is eval-val at convergence (table above).
We do not publish a Rotated Faster R-CNN 1× Hub weight; only the 3× line appears in the chart.
What improved in Oriented R-CNN 3× (eval-val) Link to heading
Biggest per-class gains vs our 1× checkpoint (same eval protocol):
| Class | 1× AP | 3× AP | Δ |
|---|---|---|---|
| bridge | 56.7% | 70.8% | +14.1 pp |
| roundabout | 69.0% | 81.6% | +12.5 pp |
| soccer-ball-field | 76.2% | 86.7% | +10.4 pp |
| swimming-pool | 59.6% | 69.1% | +9.5 pp |
| small-vehicle | 71.3% | 75.4% | +4.1 pp |
Hardest classes (ship, storage-tank) move little; extra epochs mainly help rare or structurally diverse categories.
Using the new checkpoint Link to heading
pip install oriented-det # includes Hugging Face download helpers
odet pretrained download oriented_rcnn_dota_le90_3x
In a training or inference config:
"load_from_checkpoint": "hf://oriented_rcnn_dota_le90_3x"
Demo on a single image (uses bundled recipe + sidecar config from pretrained/):
odet image-demo demo.jpg hf://oriented_rcnn_dota_le90_3x \
--out-file result.jpg --device cuda \
--score-thr 0.7 --nms-thr 0.1
Full val evaluation (needs DOTA tiles locally):
make eval-val EXPERIMENT=runs/oriented_rcnn/20260621-092802
Weights, config sidecar, and training log: pretrained/oriented_rcnn_r50_fpn_dota_le90_3x-68957f98.* · Recipe: configs/oriented_rcnn/dota_le90_3x.json
Large images: sliding-window inference Link to heading
DOTA training uses 1024×1024 tiles, but real scenes are often larger. When the input exceeds the model canvas, odet image-demo switches to pad/tile mode automatically: overlapping 1024×1024 windows, detections mapped back to full-image coordinates, then merge NMS.
Example — ship detection on demo/large.jpg (1299×1904) with the new 3× checkpoint:
odet image-demo demo/large.jpg hf://oriented_rcnn_dota_le90_3x \
--out-file result.jpg \
--score-thr 0.5 --nms-thr 0.1 \
--window-batch-size 8 --classes ship
Typical CLI output:
Preprocessing: resize_mode=fixed, target_size=(1024, 1024) (model canvas 1024×1024)
Inference thresholds: score>=0.5, merge NMS IoU<=0.1, overlap_pixels=200, ignore_margin_pixels=0.0
-> pad/tile (image 1299×1904 vs canvas 1024×1024, overlap_pixels=200, 6 windows)
-> 310 detections (score >= 0.5, NMS <= 0.1)
-> 280 after class filter ['ship'] (removed 30)
Saved visualization to result.jpg

280 oriented boxes on a dense marina scene — each docked vessel gets a rotated box aligned to its hull, with no visible seams at the six window boundaries.
What to notice:
- 6 windows for this image size — modest overhead compared with a single tile.
--window-batch-size 8batches window inference on GPU (all six windows in one pass here).--classes shipkeeps one DOTA class after detection (310 → 280 boxes).overlap_pixels=200comes from the bundled recipe default — fine for DOTA-scale objects; increase it if your targets are larger than the overlap band, or they can be split across window boundaries.--score-thr 0.5works on this harbor scene; the bundleddemo.jpgbus tile still prefers ~0.7 (see below).
For a zero-shot maritime experiment on a Copernicus Sentinel-2 tile — zoom, overlap, and margin tuned for small ships — see Zero-shot ship detection on a Copernicus Sentinel-2 tile with Oriented R-CNN.
Demo thresholds (short note) Link to heading
--score-thr and --nms-thr on odet image-demo are post-decode filters. Values tuned on one architecture do not transfer to the others: Faster R-CNN and RetinaNet typically need stricter score cutoffs on busy scenes. Oriented R-CNN 3× is still the best default on our demo.jpg bus scene at roughly --score-thr 0.7 --nms-thr 0.1.
Production NMS for Oriented R-CNN uses production.final_nms_iou_threshold: 0.3 in the recipe; 0.5 is the mAP matching IoU, not detection NMS.
Links Link to heading
- OrientedDet on GitHub
- Pretrained weights README
- Oriented R-CNN config guide
- Later in this series: Rotated Faster R-CNN with ProbIoU — 83.4% checkpoint
- Earlier posts in this series: macOS pure-Python inference, v0.1.0 release
June 29, 2026 — Jeff Faudi